
产品功能:「附近的人」是按什么规则计算的
「附近的人」这样的产品功能,你一定不陌生吧?

微信就有「附近的人」的功能,依托于位置信息,展示平台上与你距离较近的用户,这个功能在各种平台上曾经盛极一时,依托「附近的人」的功能,也产生了一些灰色的产业链。
但今天要讨论的不是如何利用「附近的人」来撩汉约P,而是站在产品的角度,分析「附近的人」是如何实现的。
如何实现?可能就是获取了个人位置信息,将平台上的所有用户的位置信息按位置排序,然后逐一计算距离…
起初我也觉得这事就这么简单。但果真如此,就不值得学习探讨了。附近的人的实现策略,并不是一句话就能说清楚的。
首先,我们来回顾一些地理知识。
1、地球是圆的,分南北极,以地轴为中心自转。
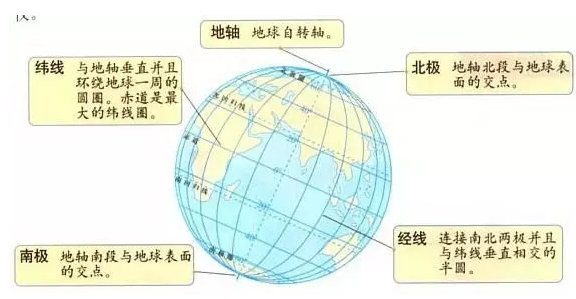
2、纵切线是经线,常用「经度」来衡量;横切线是纬线,常用「纬度」来衡量;
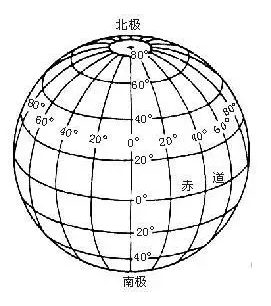
3、纬线赤道往北极方向称为「北纬」,往南极方向称为「南纬」;经线地轴往左方向是「西经」,往右方向是「西经」;经线和纬线相交的点叫「坐标」,如下图中的红点:
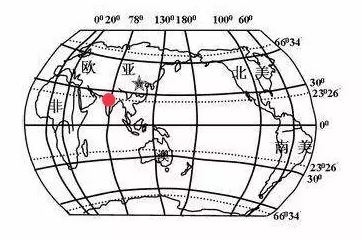
也就是说,我们每个人目前所在的位置,都在某一条经线和纬线的相交点上,都有一个「坐标」,我们也常说「位置」。
那手机应用是如何获取我们的位置的呢(手机如何定位,知道我们在哪里)?
目前常用的定位技术有GPS定位、基站定位、WiFi辅助定位、AGPS定位、Glonass定位、北斗定位等。具体这些技术是什么原理这里不细讲了,通过这些技术,我们的位置会换算成一个「坐标」,使用坐标点(XX.XXXXX,Y.XXXXX)来描述,我们也常说这是「经纬度」。
假如我们都获取到了平台上的用户位置所在的坐标点,就可以计算你和TA的距离,就知道TA是不是你附近的人了。
如何计算你和TA的距离呢?
但并不是所有用户都在同一条经线或者纬线上直接算直线距离,如果用户量较大的情况下,要这样使用二维坐标(x,y)来计算距离是不现实的,其次,真实记录用户所在的经纬度,且在多个地方使用经纬度来计算位置,有一定的隐私问题。
如果我们想要更快地得知你所在的位置附近,都有哪些人,必须寻找快一点的方式,比如数据库在数据量较大且需要排序时,会经常用到索引来提高计算效率。
GeoHash算法将二维的经纬度(x,y)转换成一维信息(字符串),同时解决了隐私问题。
以下图为例,把某个区域划分为9个格子,9个给格子分别命名为WX4ER,WX4G2、WX4G3等这样的字符串,每一个字符串是某个格子的代号,用这个代号来代表被划分的子区域。
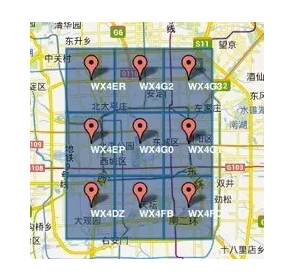
也就是说,每个格子(子区域)内所有的点(经纬度坐标)都共享相同的GeoHash字符串,大家表示自己的所在位置时,只需要说出该字符代号(比如我们在做自我介绍时说我是广州天河人,“天河”就是广州被划分的其中一个格子),这样既可以保护隐私(只表示大概区域位置而不是具体的点),一维的信息也比较容易计算和做缓存,只要格子划分地越小,距离就越精确。
那GeoHash字符串如何表示自己的精确等级呢?
GeoHash字符串越长,表示的范围越精确。如图所示,5位的编码能表示10平方千米范围的矩形区域,而6位编码能表示更精细的区域(约0.34平方千米)
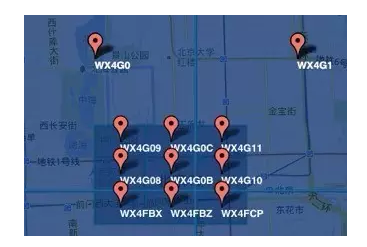
GeoHash字符串相似的表示距离相近,比如上图中的:
WX4G09和
WX4G08较近,和
WX4FBX较远
这样可以利用字符串的前缀匹配来查询附近的POI信息(POI信息表示一栋房子、一个商铺、一个邮筒、一个公交站等),在地图程序中找附近的医院、加油站等都有应用。
同样地,我们可以用此方法来圈到同一区域(格子)或者附近区域的人群,再计算大概的距离,而不用把与所有人的距离计算出来,再做排序。
再来回顾一下两种计算方法:
(1)只保存了每个人的坐标,要找出某个用户附近的人
把所有人的坐标与当前用户的坐标计算一次,算出距离
按找算出的距离升序排列,返回附近的人
(2)保存了用户的坐标+GeoHash字符串,要找出附近的人
按区域字符串相似度划出该区域的人群,区域划分越小,距离越近。
很明显,2方法要快一些。
GeoHash字符串在位置接近矩形边界时不太准确。
比如红色的点是A用户,绿色的两个点从上到下分别是B用户和C用户,但在圈定人群时会发现距离A较远的C用户的GeoHash编码与A一样(因为在同一个GeoHash区域块上),而较近的B用户的GeoHash编码与A不一样,算起来好像C与A较近。
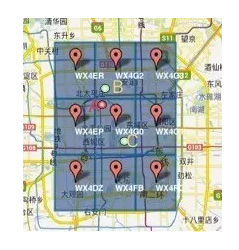
A:WX4G0
B:WX4G2
C:WX4G0
所以,除了区域的划分尽可能小来缩小边界问题,在距离要求不是很精确时,可以同时返回以A为中心区域的其他8个点附近的人。
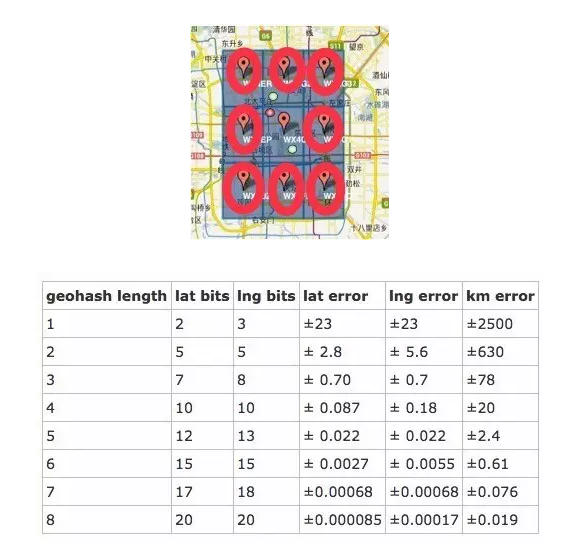
Geohash的长度越长时,表示距离越近(大部分时候准确)。如上图,6位的Geohash长度距离大概在2.4公里,8位的Geohash长度,大概在8米左右的距离误差,9位的Geohash长度,大概就是2米了。
如此,产品在准备类似附近的人这样的产品需求时,可以给到大概地理范围内的值,让研发知道你所谓的「附近」,边界在哪里。
作者:余秋楠
来源:微信公众号【程序员和产品经理】
微信就有「附近的人」的功能,依托于位置信息,展示平台上与你距离较近的用户,这个功能在各种平台上曾经盛极一时,依托「附近的人」的功能,也产生了一些灰色的产业链。
但今天要讨论的不是如何利用「附近的人」来撩汉约P,而是站在产品的角度,分析「附近的人」是如何实现的。
如何实现?可能就是获取了个人位置信息,将平台上的所有用户的位置信息按位置排序,然后逐一计算距离…
起初我也觉得这事就这么简单。但果真如此,就不值得学习探讨了。附近的人的实现策略,并不是一句话就能说清楚的。
首先,我们来回顾一些地理知识。
1、地球是圆的,分南北极,以地轴为中心自转。
2、纵切线是经线,常用「经度」来衡量;横切线是纬线,常用「纬度」来衡量;
3、纬线赤道往北极方向称为「北纬」,往南极方向称为「南纬」;经线地轴往左方向是「西经」,往右方向是「西经」;经线和纬线相交的点叫「坐标」,如下图中的红点:
也就是说,我们每个人目前所在的位置,都在某一条经线和纬线的相交点上,都有一个「坐标」,我们也常说「位置」。
那手机应用是如何获取我们的位置的呢(手机如何定位,知道我们在哪里)?
目前常用的定位技术有GPS定位、基站定位、WiFi辅助定位、AGPS定位、Glonass定位、北斗定位等。具体这些技术是什么原理这里不细讲了,通过这些技术,我们的位置会换算成一个「坐标」,使用坐标点(XX.XXXXX,Y.XXXXX)来描述,我们也常说这是「经纬度」。
假如我们都获取到了平台上的用户位置所在的坐标点,就可以计算你和TA的距离,就知道TA是不是你附近的人了。
如何计算你和TA的距离呢?
坐标值保留小数5位,大概就可以精确到1米左右,比如A用户和B用户坐标点A(20.38635,93.85210)与B(20.638635,93.85212)Y轴相差93.85212-93.85210 = 0.00002,相差在2米左右;
在纬度相等的情况下:
*经度每隔0.00001度,距离相差约1米;
*每隔0.0001度,距离相差约10米;
*每隔0.001度,距离相差约100米;
… 以此类推
*在经度相等的情况下:
*纬度每隔0.00001度,距离相差约1.1米;
*每隔0.0001度,距离相差约11米;
*每隔0.001度,距离相差约111米;
… 以此类推
但并不是所有用户都在同一条经线或者纬线上直接算直线距离,如果用户量较大的情况下,要这样使用二维坐标(x,y)来计算距离是不现实的,其次,真实记录用户所在的经纬度,且在多个地方使用经纬度来计算位置,有一定的隐私问题。
如果我们想要更快地得知你所在的位置附近,都有哪些人,必须寻找快一点的方式,比如数据库在数据量较大且需要排序时,会经常用到索引来提高计算效率。
GeoHash算法将二维的经纬度(x,y)转换成一维信息(字符串),同时解决了隐私问题。
以下图为例,把某个区域划分为9个格子,9个给格子分别命名为WX4ER,WX4G2、WX4G3等这样的字符串,每一个字符串是某个格子的代号,用这个代号来代表被划分的子区域。
也就是说,每个格子(子区域)内所有的点(经纬度坐标)都共享相同的GeoHash字符串,大家表示自己的所在位置时,只需要说出该字符代号(比如我们在做自我介绍时说我是广州天河人,“天河”就是广州被划分的其中一个格子),这样既可以保护隐私(只表示大概区域位置而不是具体的点),一维的信息也比较容易计算和做缓存,只要格子划分地越小,距离就越精确。
那GeoHash字符串如何表示自己的精确等级呢?
GeoHash字符串越长,表示的范围越精确。如图所示,5位的编码能表示10平方千米范围的矩形区域,而6位编码能表示更精细的区域(约0.34平方千米)
GeoHash字符串相似的表示距离相近,比如上图中的:
WX4G09和
WX4G08较近,和
WX4FBX较远
这样可以利用字符串的前缀匹配来查询附近的POI信息(POI信息表示一栋房子、一个商铺、一个邮筒、一个公交站等),在地图程序中找附近的医院、加油站等都有应用。
同样地,我们可以用此方法来圈到同一区域(格子)或者附近区域的人群,再计算大概的距离,而不用把与所有人的距离计算出来,再做排序。
再来回顾一下两种计算方法:
(1)只保存了每个人的坐标,要找出某个用户附近的人
把所有人的坐标与当前用户的坐标计算一次,算出距离
按找算出的距离升序排列,返回附近的人
(2)保存了用户的坐标+GeoHash字符串,要找出附近的人
按区域字符串相似度划出该区域的人群,区域划分越小,距离越近。
很明显,2方法要快一些。
GeoHash字符串在位置接近矩形边界时不太准确。
比如红色的点是A用户,绿色的两个点从上到下分别是B用户和C用户,但在圈定人群时会发现距离A较远的C用户的GeoHash编码与A一样(因为在同一个GeoHash区域块上),而较近的B用户的GeoHash编码与A不一样,算起来好像C与A较近。
A:WX4G0
B:WX4G2
C:WX4G0
所以,除了区域的划分尽可能小来缩小边界问题,在距离要求不是很精确时,可以同时返回以A为中心区域的其他8个点附近的人。
Geohash的长度越长时,表示距离越近(大部分时候准确)。如上图,6位的Geohash长度距离大概在2.4公里,8位的Geohash长度,大概在8米左右的距离误差,9位的Geohash长度,大概就是2米了。
如此,产品在准备类似附近的人这样的产品需求时,可以给到大概地理范围内的值,让研发知道你所谓的「附近」,边界在哪里。
作者:余秋楠
来源:微信公众号【程序员和产品经理】
1 个评论
有点看不懂的样子
